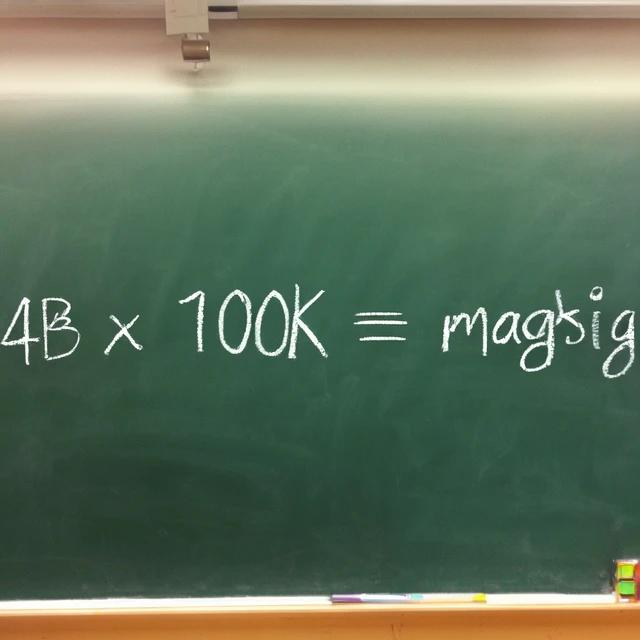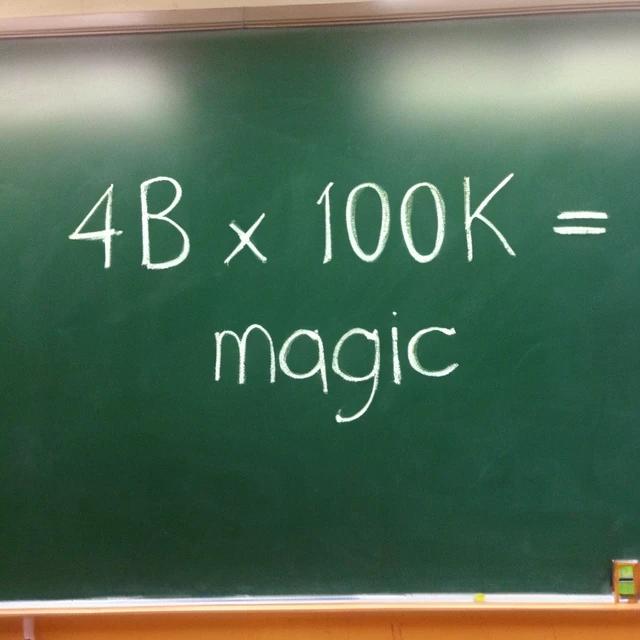TL;DR: We present Self-Flow, a
self-supervised flow matching framework. Across (a) image, (b) video,
and (c) audio generation, Self-Flow consistently outperforms REPA,
without using any external models or supervision by jointly
modeling representation and generation.
Strong semantic representations improve the convergence and generation
quality of diffusion and flow models. Existing approaches largely rely
on external models, which require separate training, operate on
misaligned objectives, and exhibit unexpected scaling behavior. We argue
that this dependence arises from the model's training objective, which
poses a denoising task with little incentive to learn semantic
representations. We introduce Self-Flow: a self-supervised flow
matching paradigm that integrates representation learning within the
generative framework. Our key mechanism,
Dual-Timestep Scheduling, applies heterogeneous noise levels
across tokens, creating an information asymmetry that forces the model
to infer missing information from corrupted inputs. This drives learning
strong representations alongside generative capabilities without
external supervision. Our method generalizes across modalities and
enables multi-modal training while following expected scaling laws,
achieving superior image, video, and audio generation.
Joint Multi-Modal Training Comparison
We benchmark our method against vanilla flow matching on a scaled
multi-modal experiment where a
single 4B parameter FLUX.2 backbone is trained to
jointly generate images, videos and audio. The results presented were
obtained with just 100k steps of high resolution
fine-tuning over a low resolution multi-modal model, on data
containing just 6M training videos and
200M training images. Our method produces significant
improvements in structural coherence (faces, hands), motion quality,
and text rendering accuracy.
Image Samples
4B parameter multi-modal model trained on
200M images for
100k high-resolution fine-tuning steps.
Vanilla
Ours
"a neon sign that says "FLUX is multimodal" glowing in rainbow
colors, dark wall."
Vanilla
Ours
"Fingernails with "LOVE" spelled across them, one letter per
nail, Valentine's style."
Vanilla
Ours
"elegant typography that says "From the Black Forest with love"
in gold and rose gold letters, dark moody forest background."
Vanilla
Ours
"a children's drawing of robot with "The future is FLUX", fridge
door."
Vanilla
Ours
"a motivational sign that says "Small model, big dreams: 4B" in
warm colors."
Vanilla
Ours
"a cute 3D robot holding a sign that says "Powered by 4B"."
Vanilla
Ours
"a prismatic crystal display that says "FLUX dreams in
multimodal", rainbow reflections."
Vanilla
Ours
"a diner sign that says "FLUX never sleeps" in retro neon,
nighttime."
Vanilla
Ours
"a birthday cake that says "FLUX creates magic" in elegant
frosting, celebration table."
Vanilla
Ours
"a theater curtain with "From words to worlds: FLUX" in gold
letters, stage."
Vanilla
Ours
"A close-up portrait of a woman with artistic avant-garde
makeup, blue eyeshadow and red lips."
Vanilla
Ours
"a neon sign that says "100K steps of training" in purple glow."
Vanilla
Ours
"A 3D animated camera character holding a sign that says "image
audio video", cartoon style."
Vanilla
Ours
"a chalkboard equation that says "4B x 100K = magic" in chalk,
classroom."
Vanilla
Ours
"A model with venetian mask makeup painted on, intricate gold
details, masquerade elegance."
Vanilla
Ours
"a LED art installation that says "FLUX dreams in multimodal",
modern museum."
Vanilla
Ours
"A child's drawing that says "Art" in crayon on paper, on a
refrigerator."
Vanilla
Ours
"A notebook that says "image audio video" in handwriting, open
on a desk."
Vanilla
Ours
"a chef's plate that says "Made with FLUX" in sauce writing,
fine dining."
Vanilla
Ours
"A cute 3D rendered speaker that says "audio" in colorful style,
simple background."
Vanilla
Ours
"a steamy mirror with "FLUX was here" writing, bathroom."
Vanilla
Ours
"a wet cement with "FLUX was here" handprints, city sidewalk."
Vanilla
Ours
"a workshop sign that says "FLUX brings ideas to life" in
industrial style, maker space."
Vanilla
Ours
"a rustic wooden letters that say "From the Black Forest of
love" in carved letters, misty path."
Vanilla
Ours
"A hand with gradient sunset nails, orange fading to purple with
silhouetted palm trees."
Vanilla
Ours
"a cooking show title "Cooking with 4B x 100K", TV studio."
Vanilla
Ours
"a campfire sign that says "Black Forest nights" in rustic
letters, camping."
Vanilla
Ours
"A quilted fabric square with "Hope" embroidered in purple
thread."
Vanilla
Ours
"a chalkboard that says "FLUX is multimodal" in white chalk."
Vanilla
Ours
"A close-up of an athlete with sweat on brow, post-workout, gym
lighting."
Vanilla
Ours
"a bumper sticker that says "Honk if you love FLUX" on car,
parking lot."
Vanilla
Ours
"a ceramic stamp that says "Made with FLUX" on pottery bottom,
craft studio."
Video Samples
4B parameter multi-modal model trained on
6M videos for
100k high-resolution fine-tuning steps.
Vanilla
Ours
"A woman does pushups, arms bending and straightening in steady
rhythm, core staying tight."
Vanilla
Ours
"A puffin returns to its burrow with a beak full of food, the
orange feet bright."
Vanilla
Ours
"A 3D animated baker pulls fresh bread from an oven, steam
rising, pleased expression."
Vanilla
Ours
"A person does tricep dips on parallel bars, seen from behind,
controlled up and down motion."
Vanilla
Ours
"A cartoon 3D rabbit munches on a carrot, ears twitching as it
chews, nose wiggling constantly."
Vanilla
Ours
"A speedboat cuts through choppy water, hull lifting as it
planes across the surface."
Vanilla
Ours
"A woman does Russian twists holding a weight, torso rotating
side to side while balancing in a V-sit."
Vanilla
Ours
"A man doing lunges with precise control."
Vanilla
Ours
"A woodworker planes a board smooth, curls of shavings rising
and falling with each stroke."
Vanilla
Ours
"Chocolate ganache pours over a cake, dark glossy coating
flowing down sides."
Vanilla
Ours
"A nurse speaks about patient care, gentle face showing
practiced compassion."
Vanilla
Ours
"A bartender builds a layered cocktail, each colored liquor
floating on the one below, the rainbow effect a triumph of
technique."
Vanilla
Ours
"A giant Pacific octopus glides along the ocean floor, the
intelligent creature moves with fluid grace."
Vanilla
Ours
"Milk pours into a small dish, creating a splash as the white
liquid overflows."
Vanilla
Ours
"Cream pours into coffee, white liquid sinking in the dark
coffee."
Vanilla
Ours
"A man exercises, pulling a weight up and down with controlled
motion."
Joint Video-Audio Samples
4B parameter multi-modal model trained on
2M audio-video pairs for
100k high-resolution fine-tuning steps. Click play to
watch baseline and ours sequentially.
Vanilla
Ours
"close up on the face of a man saying "I love the Black
Forest"."
Vanilla
Ours
"close up on the face of an animated futuristic man saying
"Welcome to the future"."
Vanilla
Ours
"a glass shattering as it hits the floor, fragments scattering
in all directions."
Vanilla
Ours
"Animation of a friendly developer in a hoodie, cozy office,
saying "Hello from the Black Forest"."
Vanilla
Ours
"close up on the face of a welcoming woman by a wooden gate,
forest path behind, saying "Come visit us"."
Vanilla
Ours
"close up on the face of a man watching AI generate content,
amazed, saying "The future is here"."
Vanilla
Ours
"a realistic video of an astronaut riding a horse saying "I love
Self-Flow"."
Vanilla
Ours
"close up on the face of a man with glasses saying "Nice to meet
you I am David"."
Vanilla
Ours
"close up on the face of a researcher in a tech lab, screens
glowing behind, saying "Welcome to Black Forest Labs"."
Vanilla
Ours
"close up on the face of a man saying "You will not believe
this"."
Vanilla
Ours
"close up on the face of an elder man by a campfire, sparks
rising, saying "Stories from the forest"."
Vanilla
Ours
"frontal view of a woman saying "Watch this"."
Vanilla
Ours
"close up on the face of a man saying "This is just the
beginning"."
Vanilla
Ours
"close up on the face of a man saying "The sky is blue"."
Vanilla
Ours
"close up on the face of a man looking around in wonder, saying
"I love the Black Forest"."
Method Overview
Illustration of our method.
Given a clean input x0, we draw two timesteps
t, s, and a random mask M, then noise
each token according to its assigned timestep. The teacher input is
noised with τmin=min{t,s},
creating an information asymmetry compared to the student. The
student is trained to simultaneously denoise the input and
reconstruct the teacher's features given its mixed-noised view.
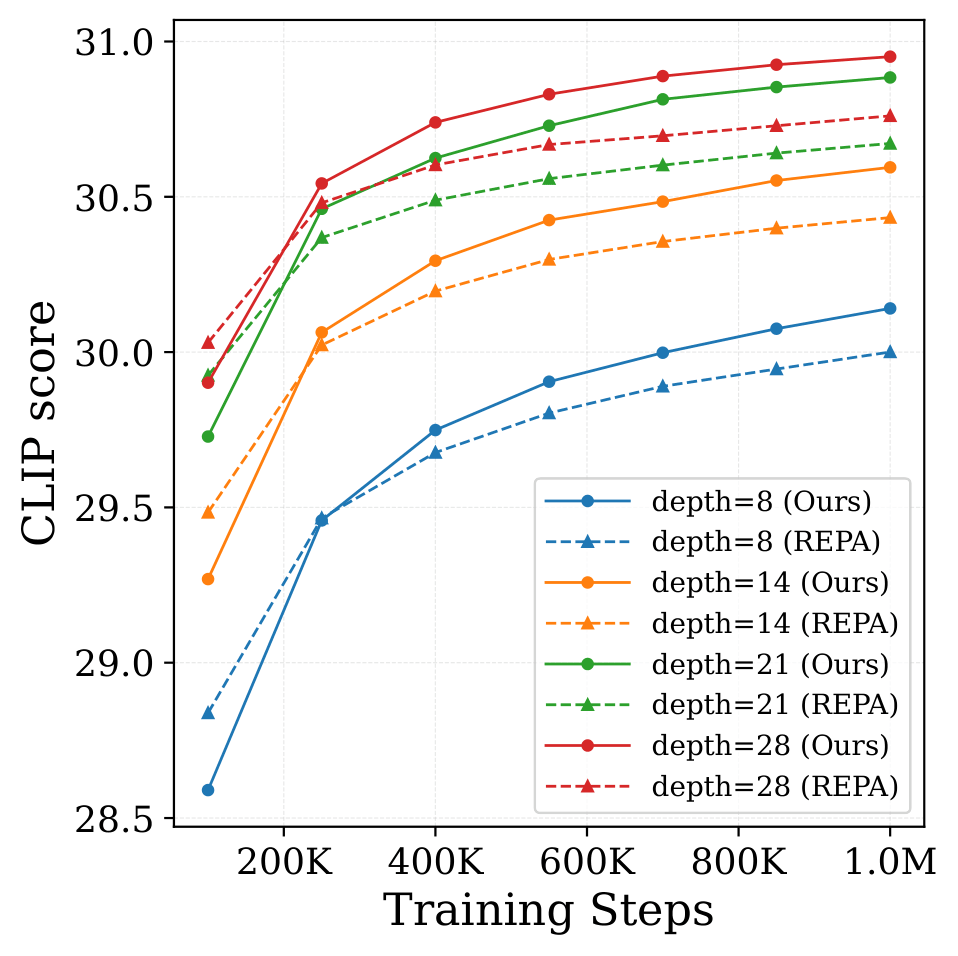
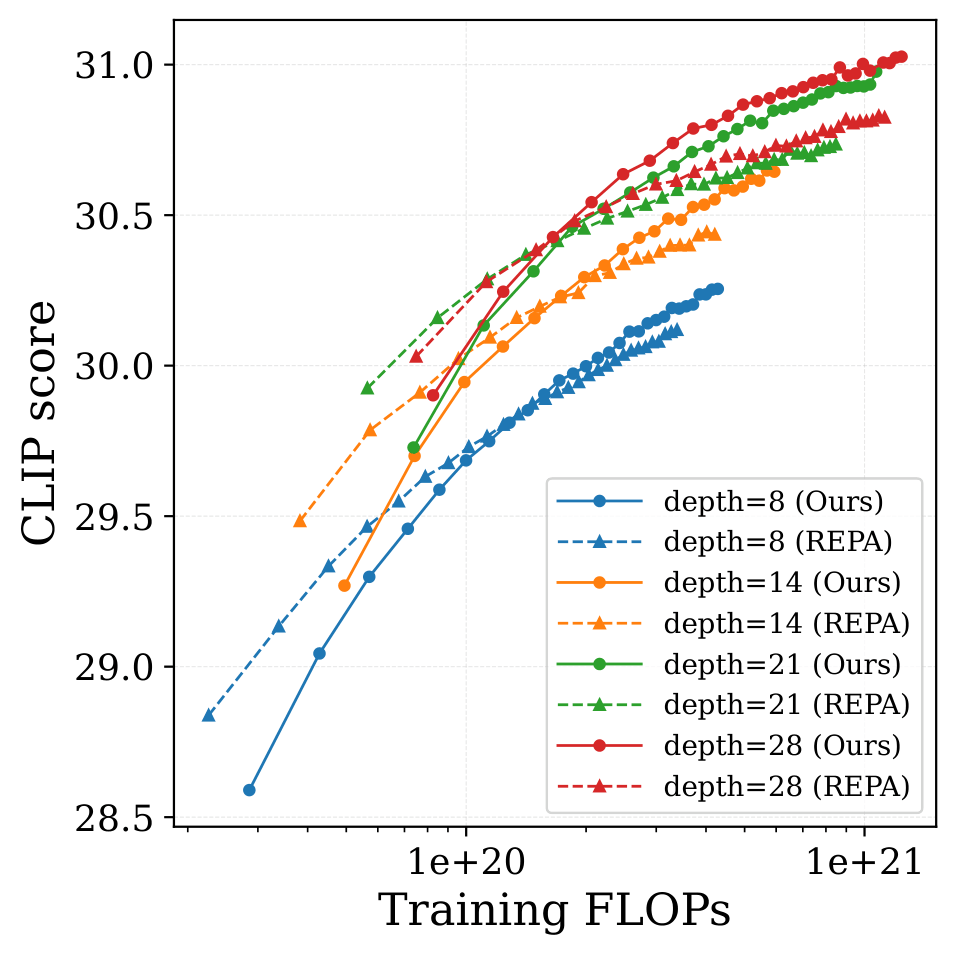
Scaling behavior (Text-to-Image). As model size
increases (290M → 420M → 625M → 1B parameters), the performance gap
between our method and REPA widens. Our method effectively leverages
increased compute, while REPA shows diminishing returns.
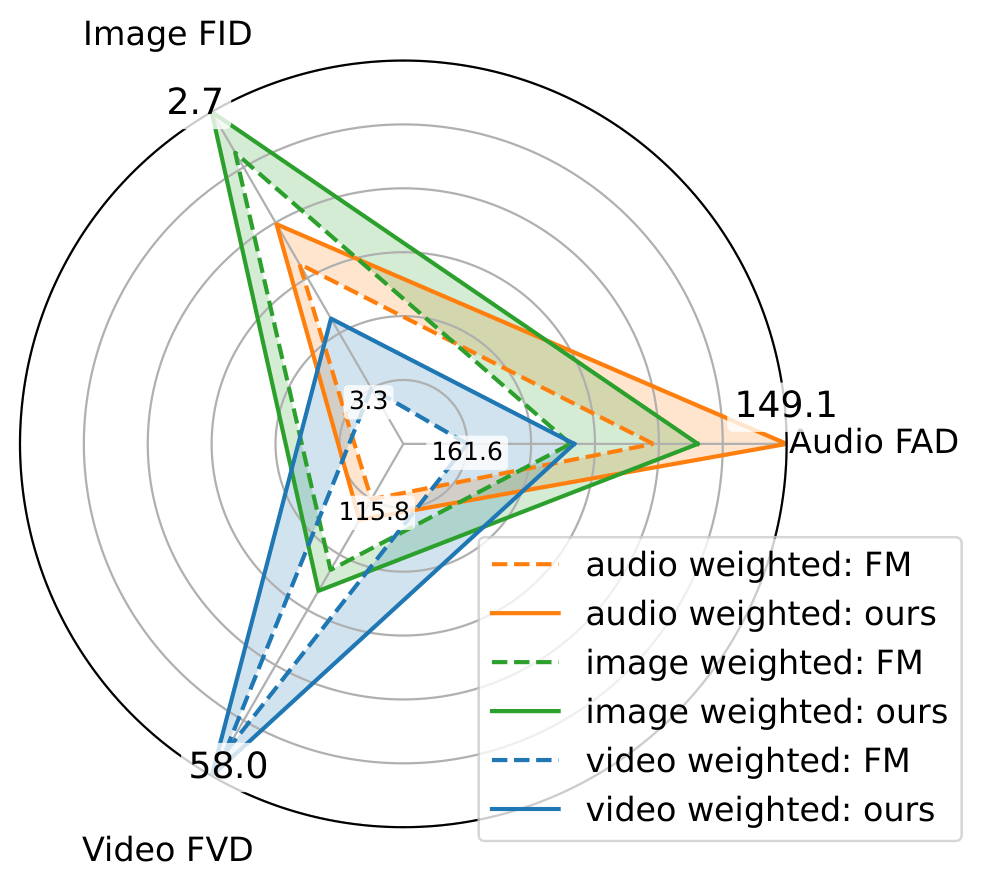
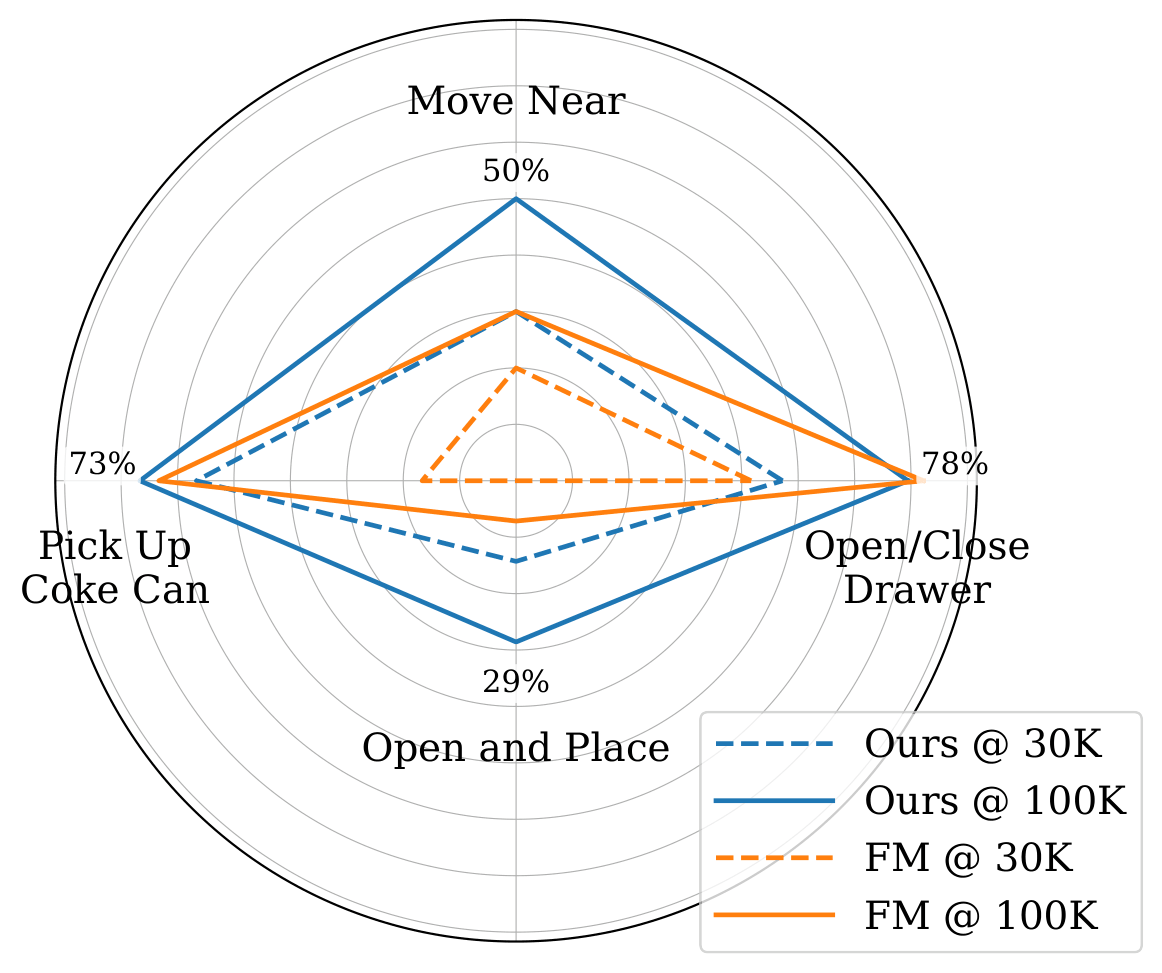
(a) Multi-Modal Training(b) Joint Video-Action Training
Multi-modal experiments. (a) We train a single
model on three modalities with different weightings to control the
trade-off between them. Self-Flow provides consistent improvements
(shaded area) across all settings. Axes are inverted so that larger
area indicates better performance. (b) Success rates for joint
Video-Action prediction. Early on (30k), Self-Flow outperforms flow
matching (FM) across all tasks and achieves success in all task
categories, whereas FM fails entirely on Open and Place tasks. Later
(100k), performance on single-object tasks (Pick Coke Can,
Open/Close Drawer) converges, while Self-Flow maintains a
significant advantage on complex multi-object and sequential tasks
(Move Near, Open and Place).
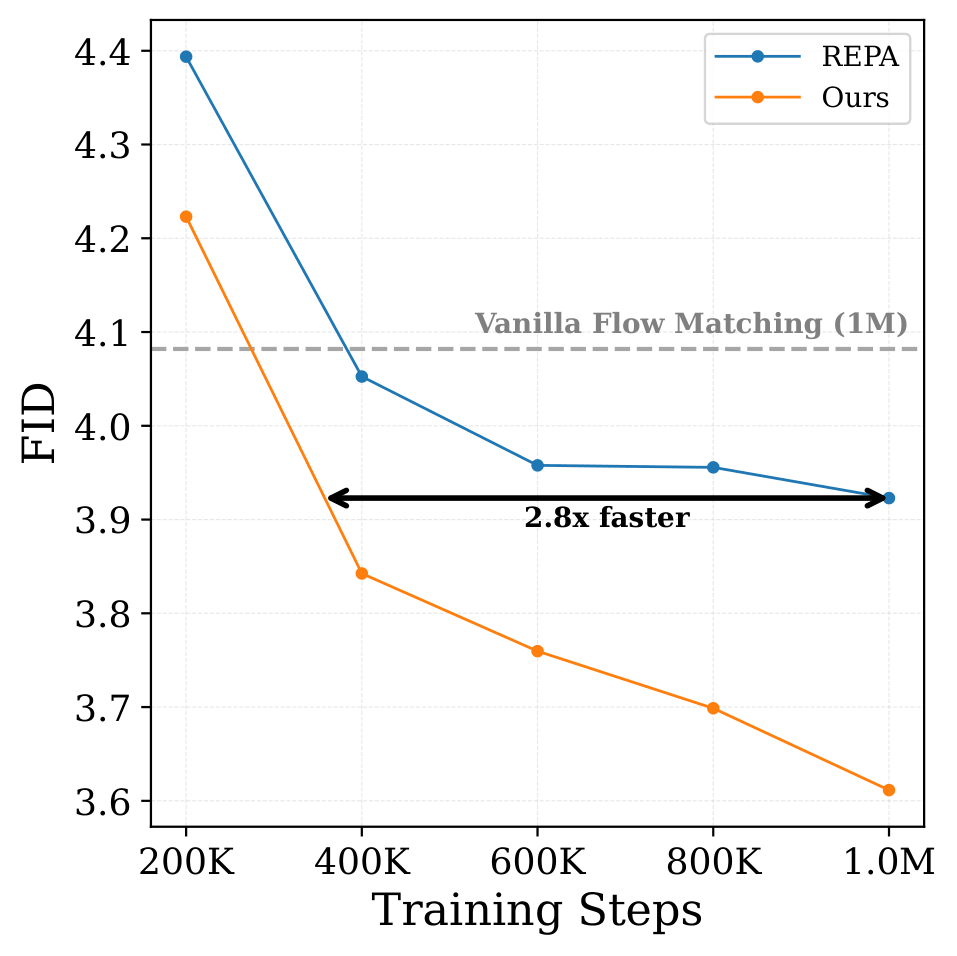
Image Generation Comparison
All models use a 625M parameter backbone trained on
20M images. We benchmark against vanilla flow
matching and leading approaches for improving diffusion
representations. For external alignment methods, we compare against
REPA with DINOv2 and REPA with SigLIP2. For methods without external
models, we compare against SRA. Our method achieves superior visual
quality and prompt adherence across diverse prompts.
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a parked blue Vespa scooter on a gravel path beside a tranquil
body of water, with tall grasses, captured in a realistic
photographic style."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a professionally portrait of a woman with medium-length dark
hair with bangs, a large white decorative bow with silver
embellishments on the side of her head."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a close-up, high-resolution photograph of a wheel and brake
system, featuring a polished silver alloy wheel with a blue
brake."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a close-up of a monkey with distinctive facial markings,
partially closed eyes, and thick fur, set against a blurred
green forest background."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a tractor, photographed in a vibrant red color, parked on a
dirt path beside a grassy field under a partly cloudy sky,
highlighting its vintage agricultural design."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a trapper hat, featuring a red and black plaid pattern with a
thick fur around the brim and ear flaps, displayed on a
mannequin head against a light background."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"an elephant standing on a dirt path in a natural, forested area
with its trunk extended downward, captured in high-definition
photography."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a softly lit portrait of a man with short hair and a beard,
wearing a dark shirt with a plaid collar, against a light
background with blurred circular elements."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a stylized, cartoon figurine of a Shiba Inu dog, depicted in a
friendly pose while holding a bowl of food, standing on a wooden
base."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a hand-painted, wooden fish-shaped decoration with horizontal
white stripes, resting on a white shelf near a window."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a bento box featuring a compartment of white rice decorated
with nori into a cartoonish face, by another compartment
containing grilled meat and vegetables."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a donkey in a grassy, fenced enclosure stands close to the
metal fence. The scene is captured in natural daylight."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a close-up, well-lit portrait photograph of a man with light
brown hair and a beard, wearing a blue and red plaid shirt,
against a plain, light-colored background."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a close-up, soft-lit photograph of a pug lying on its back on a
red textured surface, with its large, open eyes looking directly
at the camera."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a midcentury-style terracotta sculpture of a hippopotamus,
intricately detailed, seated with a decorative headdress against
a plain white background."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a close-up of the front of a car, highlighting its glossy black
paint, chrome accents,, set against a snowy outdoor background."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a donkey standing inside a stable, wearing a blue halter and a
red quilted protective blanket over its back, with wooden walls
visible in the background."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a young boy tenderly hugging a white stuffed dog toy while
standing indoors against a plain wall."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a detailed, classical-style sculpted bust of a man in a serious
expression, wearing a toga, encased in an oval frame and mounted
on a textured, earthy-toned wall."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a person wearing a black face mask with a white pattern,
standing against a green and white gradient background, captured
in a softly lit, balanced composition."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a pair of pink sneakers, worn by someone standing on a concrete
surface in an urban environment, close-up, low-angle
photograph."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a professionally lit portrait photograph of a woman with brown
hair wearing a trench coat over a white shirt captured outdoors
in natural light."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a highly detailed and colorful traditional Japanese Beckoning
Cat, depicted in a stylized manner with intricate patterns and
vibrant colors."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a photograph of a small, white church with blue trim and a
prominent blue cross on its facade, featuring a tall steeple and
situated on an elevated plot."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a photograph of plush toys—a white teddy bear and a green
rabbit—arranged together against a pink, patterned background."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"two white reindeer inside a wire-fenced enclosure, one facing
the camera and the other turned to the side; the background
includes a wooden structure."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a photograph taken from a low angle of an, highlighting its
sleek, modern design with metallic railings and overhead
structural elements under bright lighting."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a black cat in a blue jacket with red and white accents,
wearing a tag, held by a visible arm, looking upwards with its
mouth slightly open against a blue door."
Vanilla
REPA-DINO
REPA-SigLIP2
SRA
Ours
"a man posing indoors with a shallow depth of field, wearing a
dark blue shirt and sporting a friendly smile."
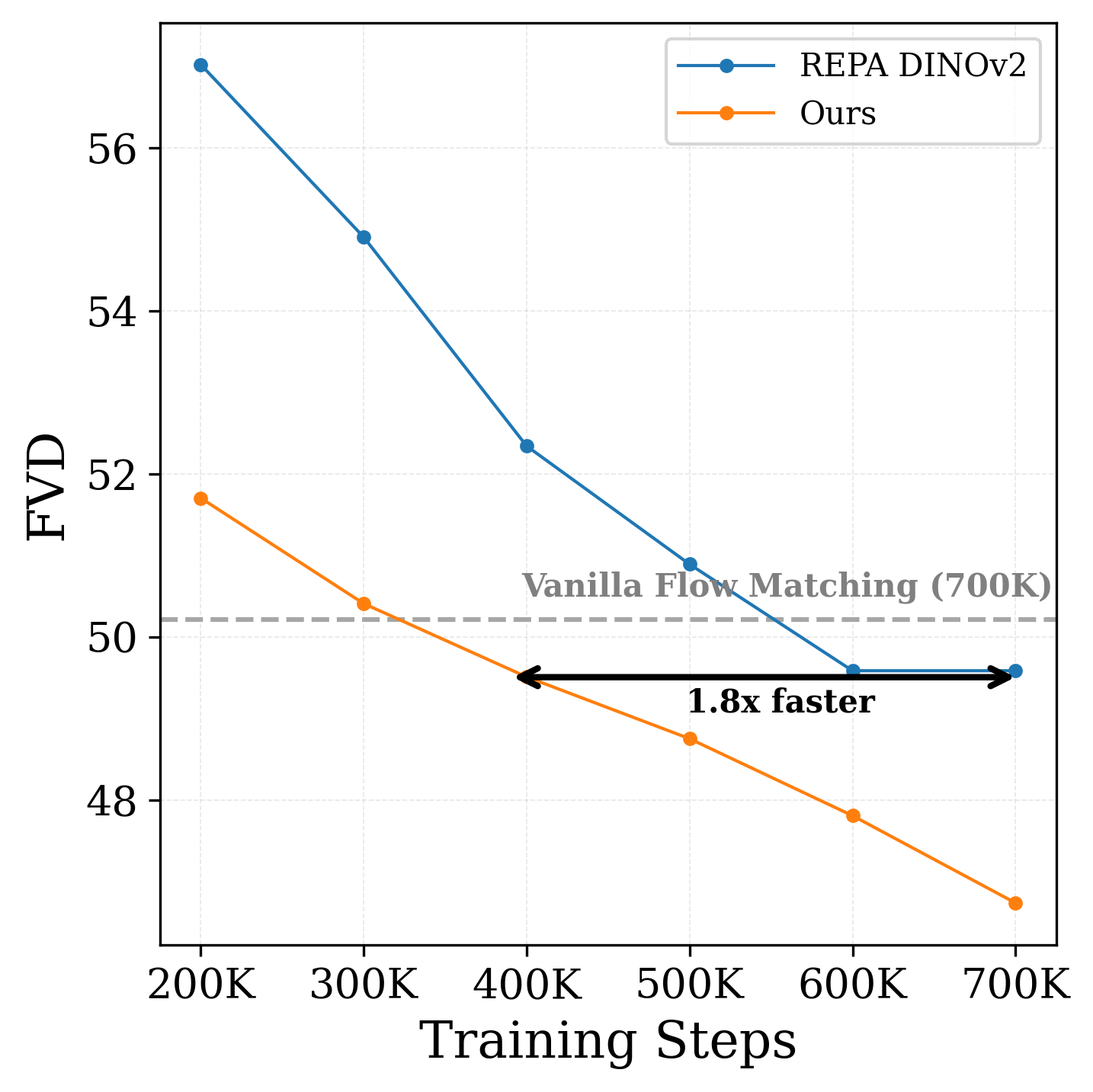
Video Generation Comparison
All models use a 625M parameter backbone trained on
just 6M videos. We compare against vanilla flow
matching, REPA with DINOv2 for external alignment, and SRA as the
leading method without external models. Interestingly, DINOv2 remains
the strongest external encoder for video generation, outperforming
video-specific encoders such as V-JEPA 2 and advanced spatial learners
such as Depth Anything 3 (see Sec. 4). Our method achieves superior
results across all baselines.
Vanilla
REPA-DINO
SRA
Ours
"a parrot preens its brilliant feathers, blue and gold colors
catching light, meticulous grooming."
Vanilla
REPA-DINO
SRA
Ours
"bicycle roll onto a wet concrete path, creating a dynamic
splash as it passes through a large puddle. The lower half of a
person's legs, clad in blue jeans, pedal the green bicycle."
Vanilla
REPA-DINO
SRA
Ours
"a first-person camera view looking down at vibrant green and
black skis, launches over a snow-covered drop revealing a vast,
sunlit mountain range."
Vanilla
REPA-DINO
SRA
Ours
"a young woman with brown hair, a white cap, denim short
overalls, and white sneakers, dances in a hip-hop style, behind
her a painted brick wall with a swirling yellow and green
spiral."
Vanilla
REPA-DINO
SRA
Ours
"an elderly man with deep wrinkles and a neatly trimmed grey
beard speaks thoughtfully to the camera. His weathered face
fills the frame as his lips form each word deliberately,
occasionally pausing to gather his thoughts, warm golden
lamplight casting gentle shadows across his features."
Vanilla
REPA-DINO
SRA
Ours
"a green sea turtle glides effortlessly through a colorful coral
reef, filmed from a low angle. The serene creature moves with
graceful flipper strokes, ancient eyes observing the vibrant
marine life, shell patterns catching the filtered sunlight in
the shallow tropical water."
Vanilla
REPA-DINO
SRA
Ours
"a 3D animated orange tries to avoid being picked, hiding behind
leaves, nervous expression."
Vanilla
REPA-DINO
SRA
Ours
"a snake slowly uncoils from its resting position, massive
length gradually revealed. The powerful constrictor moves with
undulating grace, muscular body flowing over itself as it
extends."
Vanilla
REPA-DINO
SRA
Ours
"a massive rhinoceros, seen from a low perspective, slowly walks
across a vast, dry, light-colored plain. The powerful animal
moves deliberately at a savanna landscape under a blue sky."
Vanilla
REPA-DINO
SRA
Ours
"a cartoon 3D fox trots through fallen leaves, bushy tail
swishing behind. The orange character continues on its woodland
path."
Vanilla
REPA-DINO
SRA
Ours
"a sharp chef's knife slices through a ripe red tomato on a
wooden cutting board, the blade moving in smooth, confident
strokes. Juice pools around, the knife work demonstrating years
of practiced technique."
Vanilla
REPA-DINO
SRA
Ours
"a cape bull stands its ground, facing the camera with notorious
aggression in its posture. The powerful animal's horns form a
deadly boss, one of Africa's most dangerous creatures ready to
charge."
Vanilla
REPA-DINO
SRA
Ours
"a cheese expert cuts into a perfectly aged wheel of
Parmigiano-Reggiano."
Vanilla
REPA-DINO
SRA
Ours
"an underwater view captures a large blue shark, starting with a
medium shot of its head and front body, as it gracefully turns
and begins swimming away through the deep, deep blue ocean
water. The camera smoothly tracks the shark as it performs a
swift turn."
Vanilla
REPA-DINO
SRA
Ours
"a bald man with a trimmed beard, wearing a blue hooded
sweatshirt, directs an intense and determined gaze forward, his
face illuminated by soft light. His eyes are wide and mouth
slightly open, conveying a focused, mid-sentence expression of
direct communication."
Vanilla
REPA-DINO
SRA
Ours
"zoom in on the legs of a figure skater completing a jump
combination, blades touching down. The landing is secure,
momentum carrying into the next element."
Vanilla
REPA-DINO
SRA
Ours
"a powerful male lion walks confidently across the savanna,
captured from a low angle that conveys his regal bearing. The
tawny predator moves with controlled power, mane flowing
slightly in the breeze, amber eyes scanning the horizon as he
patrols his territory under golden evening light."
Vanilla
REPA-DINO
SRA
Ours
"a silverback gorilla walks through dense jungle, seen from a
low, respectful distance. The massive ape moves with quiet
power, silver-gray back distinctive, intelligent eyes scanning
the forest."
Vanilla
REPA-DINO
SRA
Ours
"a 3D cartoon of an owl turns its head around while perched on a
tree branch at dusk, worried expression, large yellow eyes
blinking slowly."
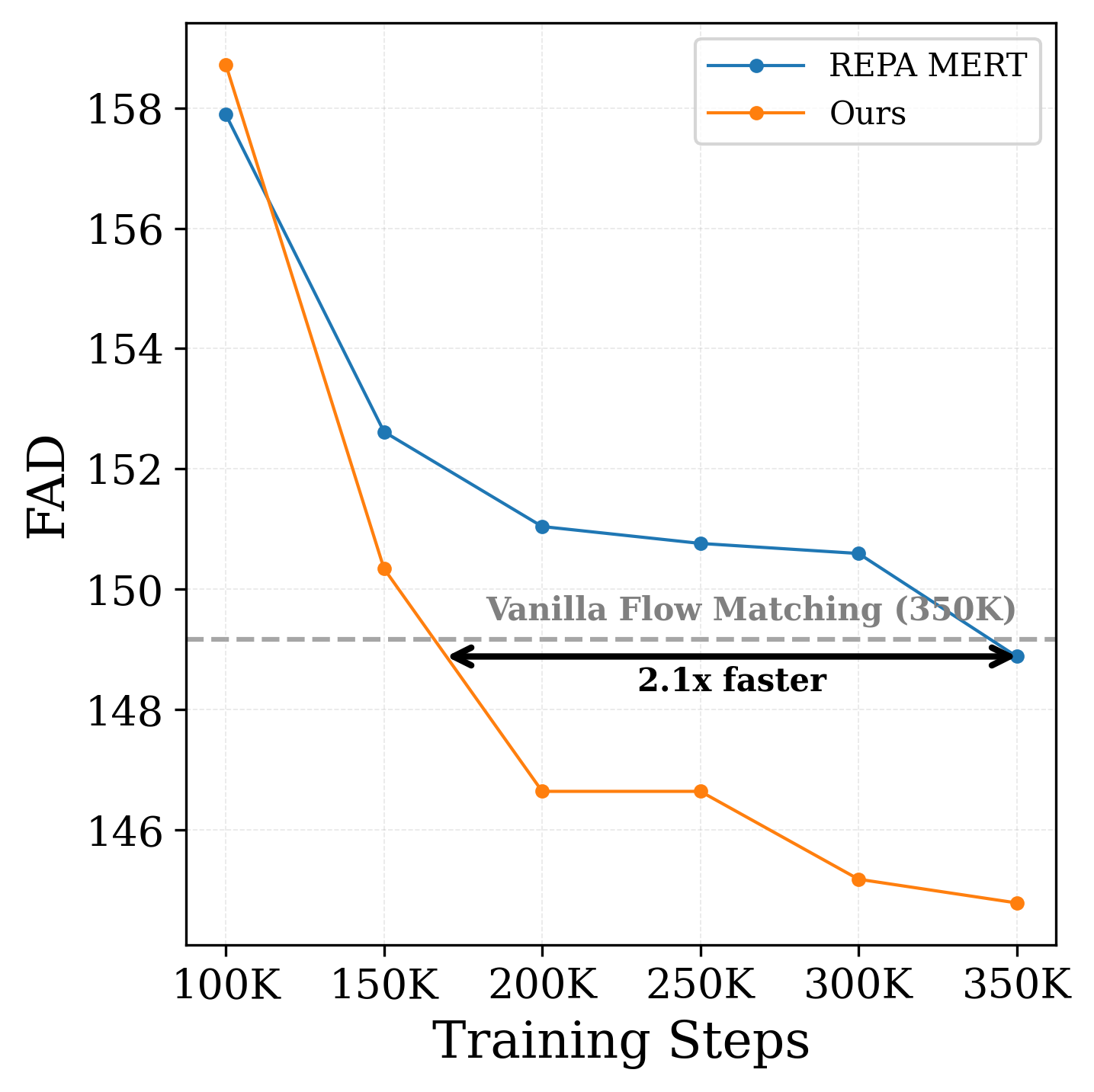
Audio Generation Comparison
All models use a 625M parameter backbone trained on
the FMA music dataset. We compare against vanilla
flow matching, REPA with MERT for external alignment, and SRA as the
leading method without external models. Consistent with our findings
on video, external alignment with MERT provides no benefit over
vanilla flow matching on audio generation (see Sec. 4), demonstrating
that external alignment fails to generalize beyond image-centric
tasks. Our method achieves superior results without relying on any
external representations.
Vanilla
MERT
SRA
Ours
"The audio features a rhythmic and energetic electronic music
track. It is characterized by a consistent, driving beat,
featuring a prominent kick drum and crisp hi-hats that establish
a strong rhythm. Layered over this percussive foundation are
distinct synth elements that contribute to the track's dynamic
and somewhat raw electronic feel, creating an engaging and
forward-moving atmosphere."
Vanilla
MERT
SRA
Ours
"The audio features energetic electronic music with a driving
beat, a prominent bassline, and a high-pitched synth melody,
layered with scratching sound effects. A male voice utters the
phrase "In the kitchen" once, and then frequently repeats the
vocal sound "Ah ah ah" throughout the track, integrating with
the rhythmic structure of the music, with the "Ah ah ah"
repeating multiple times."
Vanilla
MERT
SRA
Ours
"The audio features upbeat, energetic electronic music
characterized by a steady, driving house beat and a repetitive,
rhythmic synth melody. The track has a danceable quality, with
the synth creating a consistent, engaging groove throughout the
clip. The mood is lively and rhythmic, suitable for a club or
workout setting."
Vanilla
MERT
SRA
Ours
"The audio features a rhythmic and percussive soundscape,
dominated by a distinct drum machine beat. It prominently
features a steady, crisp hi-hat pattern, accompanied by
synthetic drum hits that resemble a snare or tom, creating a
driving, electronic rhythm. The overall mood is energetic and
mechanical."
Vanilla
MERT
SRA
Ours
"The audio features the gentle, tinkling melody of a music box,
playing a delicate and somewhat wistful tune. The distinct,
resonant sounds of the music box mechanism are clearly audible,
creating a calm and reflective atmosphere."
Vanilla
MERT
SRA
Ours
"The audio features an energetic rock music track with a driving
beat, prominent electric guitar riffs, and a strong bassline. A
male vocalist sings in English with a powerful, slightly gritty
tone, delivering the lyrics: "out of my mind, on in my head,
from your room, and into your bed." The song maintains a high
energy level throughout, driven by a steady drum rhythm,
creating an intense and passionate mood."
Vanilla
MERT
SRA
Ours
"The audio features an energetic electronic dance music track.
It begins with a driving, rhythmic beat and a looping
synthesizer melody, accompanied by various percussive electronic
sounds. A prominent 'whoosh' sound builds up, increasing
anticipation, before dropping into a more intense and
full-bodied section at around the 0:16 mark. This drop
introduces a stronger bassline and a more elaborate synth
melody, maintaining a danceable and upbeat tempo throughout the
instrumental piece, which continues with its pulsating rhythm
and evolving electronic textures."
Vanilla
MERT
SRA
Ours
"The audio features instrumental electronic music with a
distinct, somewhat melancholic and groovy feel. A steady
electronic drum beat forms the rhythmic backbone, accompanied by
a consistent bassline. The prominent melodic element is carried
by a synthesized sound that closely resembles an accordion or
bandoneon, playing a repeating, slightly soulful melody. The
overall mood is chill and contemplative, with no spoken words or
additional sound effects present throughout the clip."
Future Work — World Models
Looking ahead, by bridging representation learning and generative
modeling, our approach offers a path toward world models that harness
the scalability and perceptual grounding of visual generative models
without sacrificing the semantic abstraction required for planning and
understanding. We present results obtained by fine-tuning our
video-weighted multi-modal runs (with 675M parameters) for action
predictions. We employ the SIMPLER simulator to evaluate the action
predictions.
Flow Matching
Ours
Action: "Move Near"
Flow Matching
Ours
Action: "Close Bottom Drawer"
Flow Matching
Ours
Action: "Pick Standing Coke Can"
Flow Matching
Ours
Action: "Place Apple In Closed Top Drawer"
BibTeX
@article{CheferEsser2026selfflow,
title={Self-Supervised Flow Matching for Scalable Multi-Modal Synthesis},
author={Hila Chefer and Patrick Esser and Dominik Lorenz and Dustin Podell and Vikash Raja and Vinh Tong and Antonio Torralba and Robin Rombach},
journal = {arXiv preprint arXiv:2603.06507},
year={2026},
}