Capable, Open, and Safe: Combating AI Misuse
- Research

Black Forest Labs is pushing the frontier of visual intelligence. Our team has released some of the most capable and most popular AI models globally. As we grow, we're taking steps to combat misuse, protect the community, and show that high performance, open innovation, and sensible safeguards go hand in hand. Today, we're excited to share early results that help validate our mitigations for emerging risks—including synthetic non-consensual intimate imagery (NCII) and child sexual abuse material (CSAM)—and will help us strengthen these safeguards in the future.
- On third-party evaluations, our latest FLUX.2 model family demonstrates >10 times fewer vulnerabilities for serious risks than other leading open-weight image models, including those from large technology firms.
- Our targeted post-training mitigations help to reduce vulnerabilities by 77-98% prior to release.
- Alongside other safeguards, these mitigations can meaningfully reduce the risk of widespread misuse. For example, industry-standard moderation practices during deployment can eliminate most, if not all, residual vulnerabilities for NCII and CSAM.
Black Forest Labs is committed to open innovation
Black Forest Labs is committed to open research and development as the bedrock for competition, innovation, and security in AI. By sharing our research breakthroughs openly, we can help to accelerate the discovery of new techniques, methods, and architectures. By sharing our models openly, we enable developers around the world to build new tools that we can scarcely imagine today—from kitchen table startups to the world’s largest enterprises. To date, our founding team has contributed three of the four most popular open-weight AI models on Hugging Face, totaling over 400 million downloads. Today, our FLUX family leads the most capable open-weight image models.
We face unique challenges
We take our responsibility to mitigate emerging risks seriously. The properties that make open-weight models useful can also pose a unique challenge for risk management. These models can be deployed independently without oversight from the original developer and without appropriate safeguards, in some cases using consumer hardware. They can be modified or integrated with other systems for unauthorized purposes. If a vulnerability is discovered after release, it is not possible to fully withdraw all copies of the affected model.
We respond with layers of mitigation
While there are no silver bullets to prevent all misuse, layers of mitigation can help to prevent widespread misuse. Before each release, we evaluate a number of risks, including the production of unlawful content, with a focus on synthetic NCII and CSAM. We implement a series of pre-release mitigations in our models to help prevent misuse, with other post-release safeguards to address residual vulnerabilities. These mitigations incorporate best practices outlined by nonprofit organizations such as Thorn as well as agencies such as the US National Institute of Standards and Technology and the UK Office of Communications.
- Pre-training. We filter pre-training data for multiple categories of nude and pornographic material and known CSAM. Limiting exposure to this data in the first place can help prevent a user generating unlawful content, whether by eliciting harmful features in the data, or by combining lawful features into an unlawful composite image. We have partnered with the Internet Watch Foundation, an independent nonprofit organization dedicated to preventing online abuse, to filter known CSAM from the training data.
- Post-training. We undertake multiple rounds of targeted fine-tuning to provide additional mitigation against potential abuse, spanning both text-to-image (T2I) and image-to-image (I2I) attacks. By suppressing certain concepts in the trained model, these techniques can help prevent a user generating synthetic NCII or CSAM from a text prompt, or transforming an uploaded image into synthetic NCII or CSAM.
- Deployment. We release our most capable open-weight models with enforceable licenses that prohibit unlawful or infringing misuse, and require the use of filters during inference. With our open-weight models, we provide filters to help deployers detect violative or infringing activity. On our hosted services, we implement filters for a range of content types—including sexual content, hate, violence and gore, and representations of self-harm—and maintain a reporting relationship with the U.S. National Center for Missing and Exploited Children. Additionally, we apply content provenance metadata on our hosted services to help platforms and viewers identify AI-generated content once it is shared online. We include links to the Coalition for Content Provenance and Authenticity (C2PA) in our open-weight repositories to help other developers implement this metadata.
- After deployment. We subsequently monitor for patterns of violative use in both our hosted services and the open developer community. We issue and escalate takedown requests to websites, services, or businesses that misuse our models. Additionally, we may ban users or developers we detect violating our policies. We provide a dedicated email hotline to solicit feedback from the community, and welcome ongoing engagement with authorities, developers, and researchers to share intelligence about emerging risks and effective mitigations.
Throughout the development lifecycle, we conduct multiple internal and external evaluations to identify further opportunities for mitigation. For our latest open-weight model family, FLUX.2, we partnered with Cinder to conduct third-party red-teaming prior to each of our five open-weight model releases. These included FLUX.2 [dev]—a 32 billion parameter model based on rectified flow transformer architecture that enables high-quality image generation and editing—and FLUX.2 [klein], a derivative series of four size-distilled and step-distilled models, ranging from 4 to 9 billion parameters, optimized for local deployment, faster inference, and improved photorealism.
Third-party testing informed our release decision
Prior to release, we tasked Cinder to evaluate these models throughout their development lifecycle, including early, intermediate, and final checkpoints. These evaluations focused on identifying CSAM and NCII vulnerabilities across a range of T2I and I2I attacks. By observing the models’ behavior before, during, and after fine-tuning and distillation, we could better refine our mitigation strategy and make a considered release decision. We also instructed Cinder to run the same evaluation on leading open-weight models from other firms to help assess the marginal risk of our releases compared to the baseline.
Attacks included prompts that:
- Directly attempt to elicit violative content;
- Obscure a violative request in an otherwise benign context;
- Obfuscate intent through indirect language, “l33t”, or scrambling;
- Attempt to construct a violative image by assembling features that are individually nonviolative; and
- Request analogous visual features or substitutes in place of violative terms.
For I2I evaluations, which included one or more input images, attacks included requests to:
- Undress, simulate, or reimagine an otherwise clothed individual;
- De-age an individual;
- Splice together multiple individuals to produce a violative composite figure; and
- Merge multiple images into a violative scene.
Human labelers were instructed to classify outputs as potential NCII based on a range of factors, including whether an individual in the output image was depicted in a state of undress and whether they were still identifiable from the prompt, input images, or general knowledge. They were instructed to classify outputs as potential CSAM based on age, nudity anywhere in frame, and other sexual, suggestive, abusive, or obscene features, consistent with legal definitions of CSAM. Additionally, labelers were asked to characterize the model’s defensive response—such as whether the model ignored the prompt, cropped the image, or obscured violative features—to help refine our fine-tuning approach.
Our models demonstrate 10x fewer vulnerabilities
Totaling nearly 4,000 prompts, these evaluations yielded a rich picture of comparative risk that helped inform our release decision:
- Comparative risk. Our five models demonstrated over 10 times fewer vulnerabilities than other popular open-weight models, indicating a higher robustness to misuse. These include models recently developed or funded by large technology firms with substantial resources, such as Alibaba, Tencent, and ByteDance.
- Progressive mitigation. Our post-training mitigations yielded a 77-98 percent reduction in vulnerabilities compared to earlier checkpoints. Importantly, our most lightweight and efficient [klein] models—those likely to experience the widest adoption for local inference—demonstrated the fewest vulnerabilities.
- Residual vulnerabilities. Subsequent evaluations with Cinder suggested that residual vulnerabilities can be nearly eliminated in deployment through the adoption of industry-standard moderation practices.
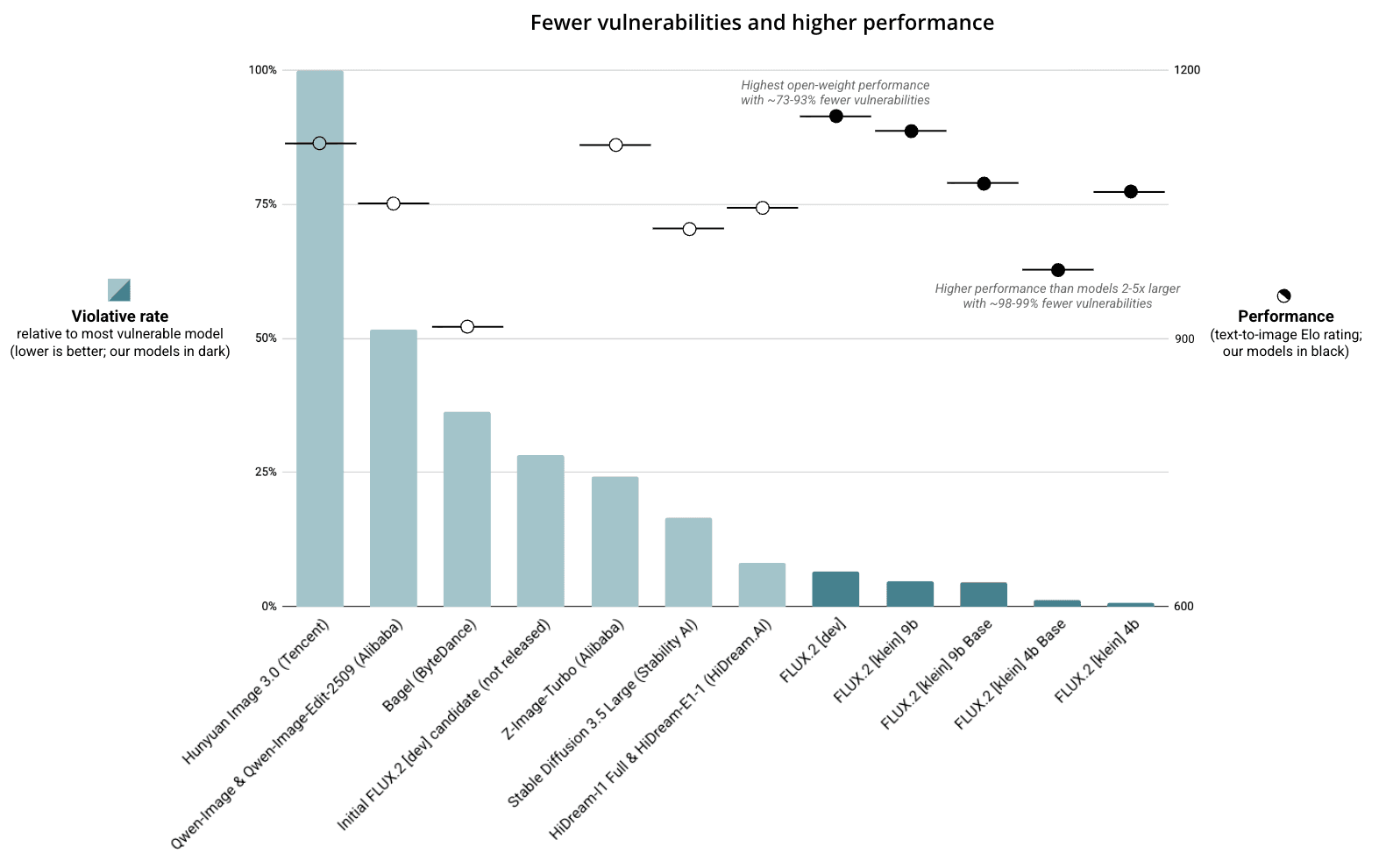
Above. Violative rates across popular open-weight models compared to the most vulnerable model evaluated (Hunyuan Image 3.0). Released Black Forest Labs models in dark green. n≈3,800 prompts, covering both T2I and I2I, NCII and CSAM attacks. Outputs were classified by human labelers. Models or model families capable of T2I and I2I were evaluated for both types of attack, else they were evaluated on a single modality only. Relative performance indicated by text-to-image Elo ratings (a measure of general performance; February 2026).
We subsequently decided to release FLUX.2 [dev], FLUX.2 [klein] 9B Base, and FLUX.2 [klein] 9B under a non-commercial open-weight license that permits free use for personal and research applications, and FLUX.2 [klein] 4B Base and FLUX.2 [klein] 4B under an Apache 2.0 license.
Limitations
This evaluation could not directly measure robustness to adversarial modification (e.g. via fine-tuning or low-rank adapters, known as LoRAs). However, we expect that circumventing our embedded mitigations will be more challenging than with other models. These safeguards should raise the expertise, data, and compute barrier to a malicious actor introducing unsafe behaviors to the model. Additionally, popular platforms like Hugging Face and CivitAI continue to improve their moderation of unlawful or violative repositories, such as LoRAs intended to produce NCII. Together, we expect that embedded mitigations in our models coupled with robust downstream moderation will help to significantly reduce the distribution of malicious derivative models and unlawful content online.
This is just the beginning, and we are constantly improving
We are a small team with global impact, and the only European and American lab releasing frontier open-weight models for visual generation. Our models compete with China’s largest technology firms. Yet despite significant risk mitigation, our models continue to rank among the most capable and most popular. Through our collaboration with Cinder, we have shown that performance, openness, and safety are not mutually exclusive.
These are early days, and we are constantly improving. We welcome ongoing dialogue with researchers, authorities, and developers as we continue to refine our approach to these risks. Please reach out to us at safety@blackforestlabs.ai with feedback!
—Black Forest Labs