- Models
- News
- Research
FLUX.2 [klein]: Towards Interactive Visual Intelligence
![FLUX.2 [klein]: Towards Interactive Visual Intelligence](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2F2gpum2i6%2Fproduction%2F41055678178f6fe75ca618b854b195e48dfc55ed-2127x1400.jpg&w=3840&q=75)
FLUX.2 [klein]: Towards Interactive Visual Intelligence
Today, we release the FLUX.2 [klein] model family, our fastest image models to date. FLUX.2 [klein] unifies generation and editing in a single compact architecture, delivering state-of-the-art quality with end-to-end inference as low as under a second. Built for applications that require real-time image generation without sacrificing quality, and runs on consumer hardware with as little as 13GB VRAM.

Demo showing editing with FLUX.2 [klein]
Why go [klein]?
Visual Intelligence is entering a new era. As AI agents become more capable, they need visual generation that can keep up; models that respond in real-time, iterate quickly, and run efficiently on accessible hardware.
The klein name comes from the German word for "small", reflecting both the compact model size and the minimal latency. But FLUX.2 [klein] is anything but limited. These models deliver exceptional performance in text-to-image generation, image editing and multi-reference generation, typically reserved for much larger models.
What's New
- Sub-second inference. Generate or edit images in under 0.5s on modern hardware.
- Photorealistic outputs and high diversity, especially in the base variants.
- Unified generation and editing. Text-to-image, image editing, and multi-reference support in a single model while delivering frontier performance.
- Runs on consumer GPUs. The 4B model fits in ~13GB VRAM (RTX 3090/4070 and above).
- Developer-friendly & Accessible: Apache 2.0 on 4B models, open weights for 9B models. Full open weights for customization and fine-tuning.
- API and open weights. Production-ready API or run locally with full weights.
Note: The “FLUX [dev] Non-Commercial License” has been renamed to “FLUX Non-Commercial License” and will apply to the 9B Klein models. No material changes have been made to the license.
Text to Image collage using FLUX.2 [klein]
The FLUX.2 [klein] Model Family
FLUX.2 [klein] 9B
Our flagship small model. Defines the Pareto frontier for quality vs. latency across text-to-image, single-reference editing, and multi-reference generation. Matches or exceeds models 5x its size - in under half a second. Built on a 9B flow model with 8B Qwen3 text embedder, step-distilled to 4 inference steps.
Combine multiple input images, blend concepts, and iterate on complex compositions - all at sub-second speed with frontier-level quality. No model this fast has ever done this well.
License: FLUX NCL

Imagine editing collage using FLUX.2 [klein]
FLUX.2 [klein] 4B:
Fully open under Apache 2.0. Our most accessible model, it runs on consumer GPUs like the RTX 3090/4070. Compact but capable: supports T2I, I2I, and multi-reference at quality that punches above its size. Built for local development and edge deployment.
License: Apache 2.0
FLUX.2 [klein] Base 9B / 4B:
The full-capacity foundation models. Undistilled, preserving complete training signal for maximum flexibility. Ideal for fine-tuning, LoRA training, research, and custom pipelines where control matters more than speed. Higher output diversity than the distilled models.
License: 4B Base under Apache 2.0, 9B Base under FLUX NCL

Output Diversity using FLUX.2 [klein]
Quantized versions
We are also releasing FP8 and NVFP4 versions of all [klein] variants, developed in collaboration with NVIDIA for optimized inference on RTX GPUs. Same capabilities, smaller footprint - compatible with even more hardware.
- FP8: Up to 1.6x faster, up to 40% less VRAM
- NVFP4: Up to 2.7x faster, up to 55% less VRAM
Benchmarks on RTX 5080/5090, T2I at 1024×1024
Same licenses apply: Apache 2.0 for 4B variants, FLUX NCL for 9B.
Performance Analysis
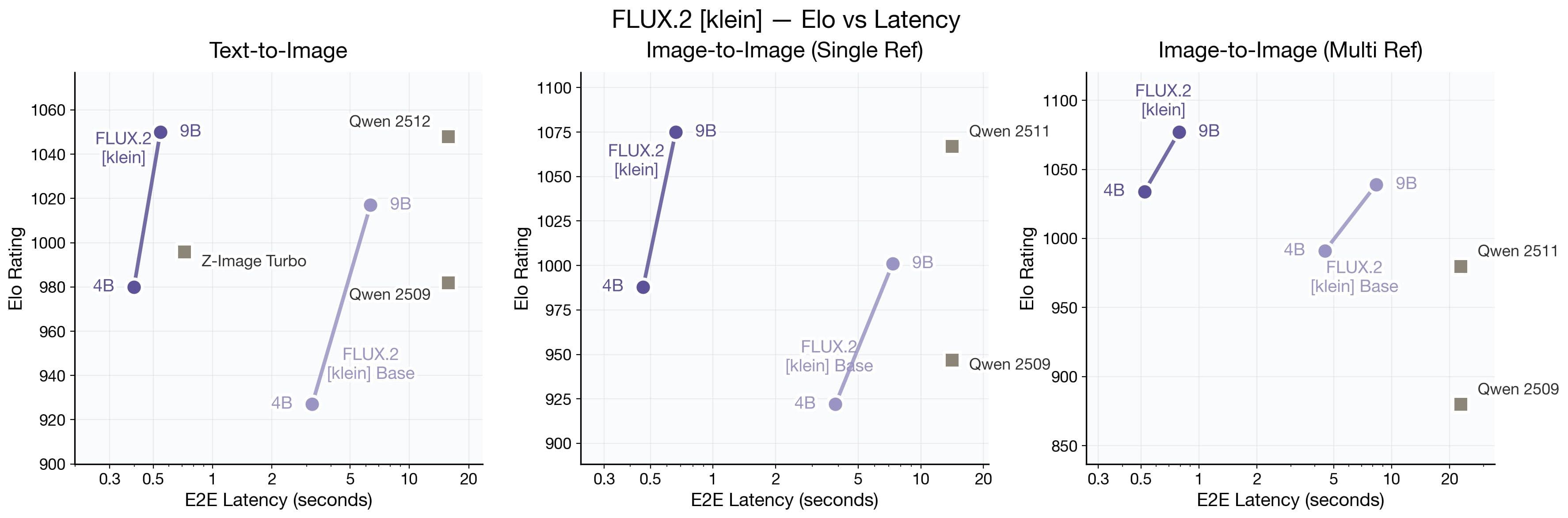
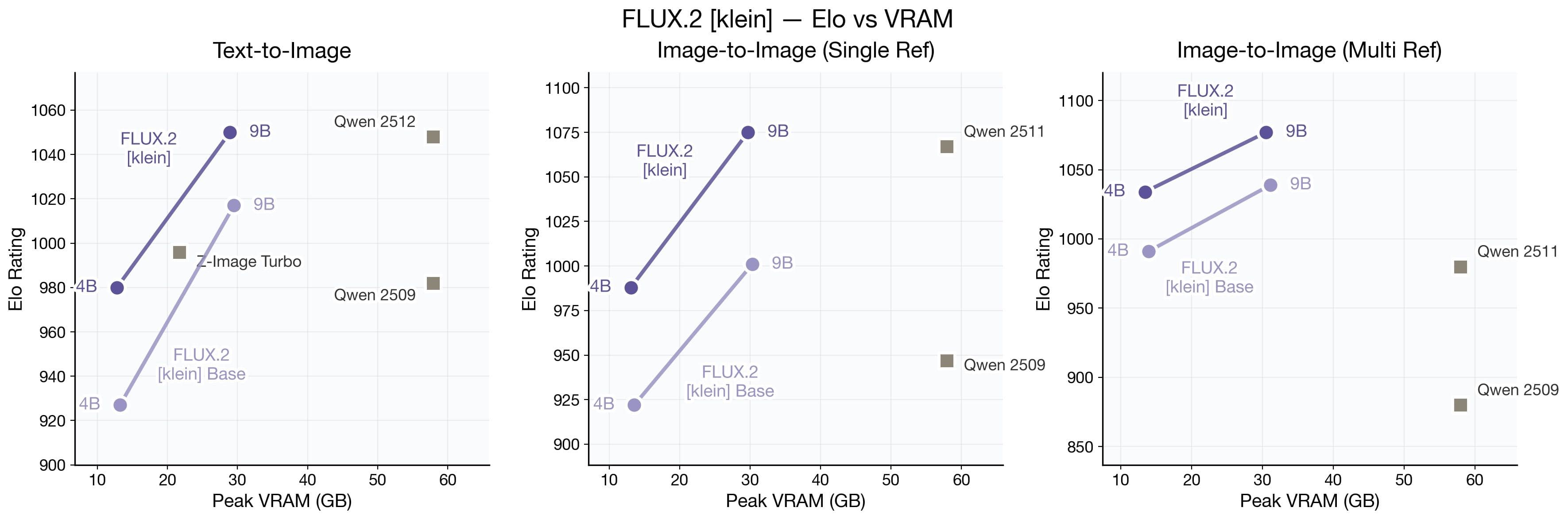
FLUX.2 [klein] Elo vs Latency (top) and VRAM (bottom) across Text-to-Image, Image-to-Image Single Reference, and Multi-Reference tasks. FLUX.2 [klein] matches or exceeds Qwen's quality at a fraction of the latency and VRAM, and outperforms Z-Image while supporting both text-to-image generation and (multi-reference) image editing in a unified model. The base variants trade some speed for full customizability and fine-tuning, making them better suited for research and adaptation to specific use cases. Speed is measured on a GB200 in bf16.
Into the New
FLUX.2 [klein] is more than a faster model. It's a step toward our vision of interactive visual intelligence. We believe the future belongs to creators and developers with AI that can see, create, and iterate in real-time. Systems that enable new categories of applications: real-time design tools, agentic visual reasoning, interactive content creation.
Resources
Try it
Build with it
Learn more