FLUX.2: Frontier Visual Intelligence
- NewsModelsResearch

FLUX.2 is designed for real-world creative workflows, not just demos or party tricks. It generates high-quality images while maintaining character and style consistency across multiple reference images, following structured prompts, reading and writing complex text, adhering to brand guidelines, and reliably handling lighting, layouts, and logos. FLUX.2 can edit images at up to 4 megapixels while preserving detail and coherence.
Black Forest Labs: Open Core
We believe visual intelligence should be shaped by researchers, creatives, and developers everywhere, not just a few. That’s why we pair frontier capability with open research and open innovation, releasing powerful, inspectable, and composable open-weight models for the community, alongside robust, production-ready endpoints for teams that need scale, reliability, and customization.
When we launched Black Forest Labs in 2024, we set out to make open innovation sustainable, building on our experience developing some of the world’s most popular open models. We’ve combined open models like FLUX.1 [dev]—the most popular open image model globally—with professional-grade models like FLUX.1 Kontext [pro], which powers teams from Adobe to Meta and beyond. Our open core approach drives experimentation, invites scrutiny, lowers costs, and ensures that we can keep sharing open technology from the Black Forest and the Bay into the world.
From FLUX.1 to FLUX.2
Precision, efficiency, control, extreme realism - where FLUX.1 showed the potential of media models as powerful creative tools, FLUX.2 shows how frontier capability can transform production workflows. By radically changing the economics of generation, FLUX.2 will become an indispensable part of our creative infrastructure.

Output Versatility: FLUX.2 is capable of generating highly detailed, photoreal images along with infographics with complex typography, all at resolutions up to 4MP
What’s New
- Multi-Reference Support: Reference up to 10 images simultaneously with the best character / product / style consistency available today.
- Image Detail & Photorealism: Greater detail, sharper textures, and more stable lighting suitable for product shots, visualization, and photography-like use cases.
- Text Rendering: Complex typography, infographics, memes and UI mockups with legible fine text now work reliably in production.
- Enhanced Prompt Following: Improved adherence to complex, structured instructions, including multi-part prompts and compositional constraints.
- World Knowledge: Significantly more grounded in real-world knowledge, lighting, and spatial logic, resulting in more coherent scenes with expected behavior.
- Higher Resolution & Flexible Input/Output Ratios: Image editing on resolutions up to 4MP.

All variants of FLUX.2 offer image editing from text and multiple references in one model.
Available Now
The FLUX.2 family covers a spectrum of model products, from fully managed, production-ready APIs to open-weight checkpoints developers can run themselves. The overview graph below shows how FLUX.2 [pro], FLUX.2 [flex], FLUX.2 [dev], and FLUX.2 [klein] balance performance, and control
- FLUX.2 [pro]: State-of-the-art image quality that rivals the best closed models, matching other models for prompt adherence and visual fidelity while generating images faster and at lower cost. No compromise between speed and quality. → Available now at BFL Playground, the BFL API and via our launch partners.
- FLUX.2 [flex]: Take control over model parameters such as the number of steps and the guidance scale, giving developers full control over quality, prompt adherence and speed. This model excels at rendering text and fine details. → Available now at bfl.ai/play , the BFL API and via our launch partners.
- FLUX.2 [dev]: 32B open-weight model, derived from the FLUX.2 base model. The most powerful open-weight image generation and editing model available today, combining text-to-image synthesis and image editing with multiple input images in a single checkpoint. FLUX.2 [dev] weights are available on Hugging Face and can now be used locally using our reference inference code. On consumer grade GPUs like GeForce RTX GPUs you can use an optimized fp8 reference implementation of FLUX.2 [dev], created in collaboration with NVIDIA and ComfyUI. You can also sample Flux.2 [dev] via API endpoints on FAL, Replicate, Runware, Verda, TogetherAI, Cloudflare, DeepInfra. For a commercial license, visit our website.
- FLUX.2 [klein] (coming soon): Open-source, Apache 2.0 model, size-distilled from the FLUX.2 base model. More powerful & developer-friendly than comparable models of the same size trained from scratch, with many of the same capabilities as its teacher model. Join the beta
- FLUX.2 - VAE: A new variational autoencoder for latent representations that provide an optimized trade-off between learnability, quality and compression rate. This model provides the foundation for all FLUX.2 flow backbones, and an in-depth report describing its technical properties is available here. The FLUX.2 - VAE is available on HF under an Apache 2.0 license.


Generating designs with variable steps: FLUX.2 [flex] provides a “steps” parameter, trading off typography accuracy and latency. From left to right: 6 steps, 20 steps, 50 steps.

Controlling image detail with variable steps: FLUX.2 [flex] provides a “steps” parameter, trading off image detail and latency. From left to right: 6 steps, 20 steps, 50 steps.
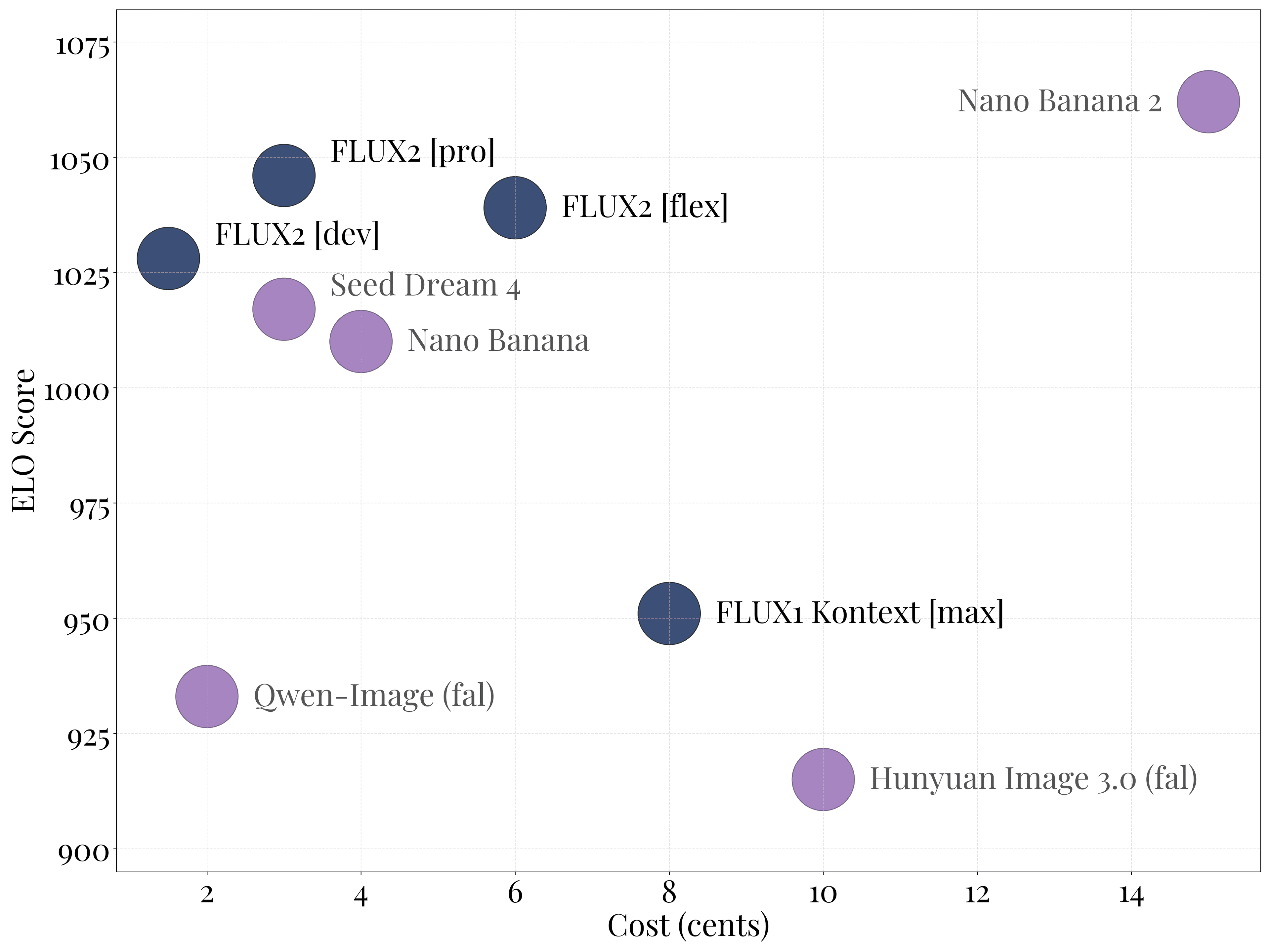
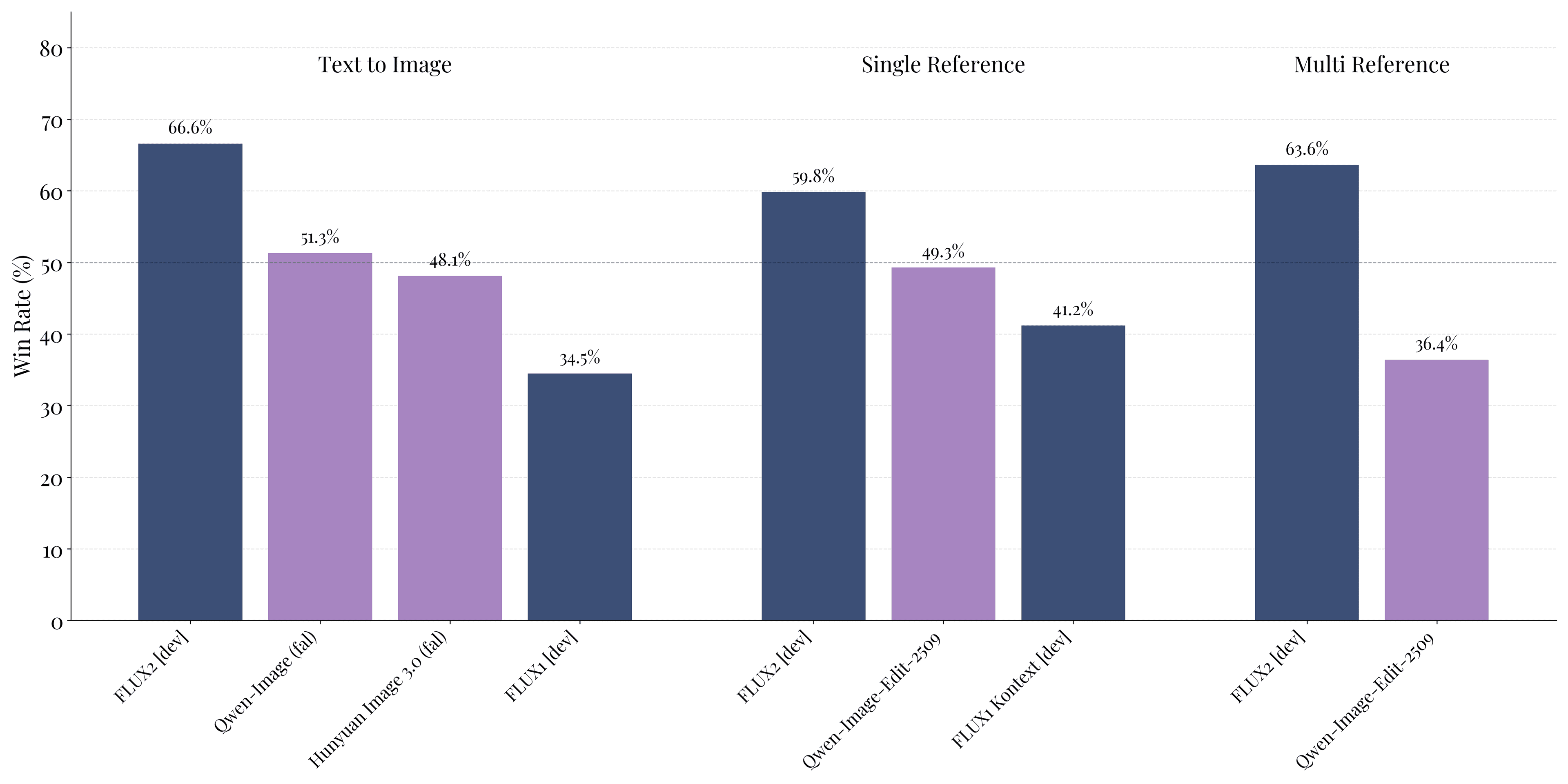
The FLUX.2 model family delivers state-of-the-art image generation quality at extremely competitive prices, offering the best value across performance tiers.
For open-weights image models, FLUX.2 [dev] sets a new standard, achieving leading performance across text-to-image generation, single-reference editing, and multi-reference editing, consistently outperforming all open-weights alternatives by a significant margin.
Whether open or closed, we are committed to the responsible development of these models and services before, during, and after every release.
How It Works
FLUX.2 builds on a latent flow matching architecture, and combines image generation and editing in a single architecture. The model couples the Mistral-3 24B parameter vision-language model with a rectified flow transformer. The VLM brings real world knowledge and contextual understanding, while the transformer captures spatial relationships, material properties, and compositional logic that earlier architectures could not render.
FLUX.2 now provides multi-reference support, with the ability to combine up to 10 images into a novel output, an output resolution of up to 4MP, substantially better prompt adherence and world knowledge, and significantly improved typography. We re-trained the model’s latent space from scratch to achieve better learnability and higher image quality at the same time, a step towards solving the “Learnability-Quality-Compression” trilemma. Technical details can be found in the FLUX.2 VAE blog post.
More Resources:
Into the New
We're building foundational infrastructure for visual intelligence, technology that transforms how the world is seen and understood. FLUX.2 is a step closer to multimodal models that unify perception, generation, memory, and reasoning, in an open and transparent way.
Join us on this journey. We're hiring in Freiburg (HQ) and San Francisco. View open roles.